I. Intro
지난 번 WSL에서 Jupyter notebook을 사용하게 되었는데, 사실 Python은 여러 가지 패키지 상의 문제나 시스템 상의 이유로 다양한 버전을 다운로드 받아서 사용하고 있는 경우가 많습니다. 저의 경우에도 인제 막 시작한 Django를 혼자 쓸 때나 데이터 분석 툴들을 사용할 때에는 Python3.8을 사용하지만, 동아리에서 진행하는 Django sesison이나 Tensorflow를 건드려 볼때에는 3.8 버전이 아직 나오지 않아서 3.7 버전을 어쩔 수 없이 사용하게 됩니다. 그래서, 이 두 개의 버전을 Jupyter notebook에 사용하고 싶어서 처음에는 따로 따로 다운 받아서 사용하면 된다고 생각을 하였습니다.
python3.8 -m pip install jupyter notebook
python3.7 -m pip install jupyter notebook
이렇게 깔아주고 패키지 관리를 각각 파이썬 별로 해주면 됩니다. 근데, 이렇게 되었을 때 jupyter notebook에 가서 다음과 같은 명령어로 버전을 확인해주면,
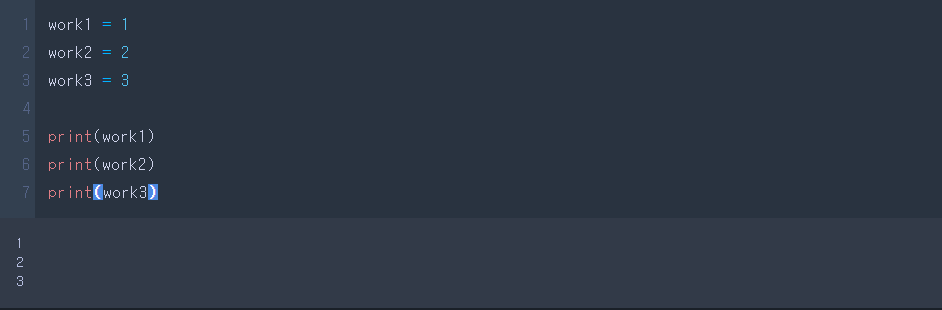
import sys
sys.version
아마 처음에 깔린 python 버전만 나오지, python3.7 -m jupyter notebook이라는 명령어로 실행시키더라도 python3.8이 실행되는 분통터지는 모습을 볼 수가 있을 겁니다. 이러한 일이 일어나는 이유는 무엇이고, 어떤 방법으로 해결할 수가 있을까요?
II. 들어가기전 개념 정리

보통은 많은 패키지들은 위의 방식과 같이 각각의 Python version에 대해서 하나씩 깔리는 형태를 취하고 있습니다. 때문에 Python3.7 버전에서 다운 받은 django, pandas, numpy와 같은 패키지들이 3.8에서 사용되지 않는 것은 의존성이 각각의 버전에 맞추어져있고, 따로 따로 깔아서 사용해주어야 한다는 점으로 볼 수가 있을 겁니다.
Jupyter notebook은 어떨까요?

Jupyter notebook의 경우에도 pip를 사용하여 깔 수 있으나 조금은 다른 방식으로 접근을 해주어야한다는 것을 알 수가 있습니다. 바로 R과 같은 다른 언어에서도 기존의 Jupyter Notebook을 이용하여 사용할 수 있다는 점인데요. 아까의 패키지가 각각의 버전에 따로 깔려서 사용한다면 R에서는 작동이 되지 않아야하는데, R과 같은 다른 언어에서도 사용할 수 있다는 점이 살짝 이상하게 다가오긴 합니다. 때문에 관계는 다음과 같게 설정됨을 알 수가 있습니다.

여기서 저희는 이런 프로그램 언어들이 돌아갈 수 있는 환경을 커널이라고 부르고 있습니다.
각각의 python3.7 python3.8 R과 같은 커널들이 존재를 하고 이 언어들을 Jupyter Notebook에 인식을 시켜서 우리는 Jupyter Notebook을 통해서 파일을 수정하고 실행을 해보게 됩니다. 때문에, python 다른 버전에서 설치를 해도, 이미 설치가 되어있는데, 뭘 설치를 하라는건지 컴퓨터에서는 아리송할 수 밖에 없는 것이죠. 만약 하나에 설치가 되어 있으면 커널 추가를 통해서 문제를 해결 할 수 있습니다.
III. 커널 추가


먼저 저의 상태는 python3이라는 python3.8의 버전이 깔려 있습니다. 여기에 3.7을 추가해보도록 하겠습니다.
입력할 명령어는
python3.7 -m pip insatll ipykernel
python3.7 -m ipykernel install --user --name="이름"
입니다. 이 때 추가를 원하는 버전의 python을 기준으로 앞의 python3.7 버전을 수정시켜주시면 되고, 이름의 경우에는 원하시는 인식명을 적어주시면 됩니다. 저의 경우에는 "Python(3.7)"로 하게 되었습니다.
이후 추가 되었다는 결과문이 나오게 되고 jupyter notebook을 다시 실행시켜주게 되면.


다만 Default로 설정되어있는 값이 존재를 하기 때문에, Jupyter notebook 파일을 열고나서는 커널을 기본 커널이 아닌 다른 커널로 변경을 해주셔야합니다.
'Programming > Python' 카테고리의 다른 글
| Programming tip - Meta Programming (0) | 2020.04.04 |
|---|